Under The Bonnet: Representing Characters and Strings.

ASCII, Unicode and UTF-8! The story of character encoding.
In previous post, we’ve already discussed about how we interpret bit and bytes to integer and vice-versa, how to represent integers in bit and bytes. There is one thing that is as important as numbers: words, sentences. We need some way to represent those in bit and bytes.
Under The Bonnet: Binary Representation of Integer
Again, a disclaimer, this series are written for those who has no chance on formally study about this things like me. Hence, the (over)simplification of many things.

Bart and UTF-8
In the olden times, there was ASCII
Computer was largely American thing. This is reflected to how alphabet are represented in memory. The first character encoding set used in computer and becomes pretty popular was created by The American Standard Code for Information Interchange or ASCII in short. This character set maps 7-bit number to English characters and symbol. Here’s the table
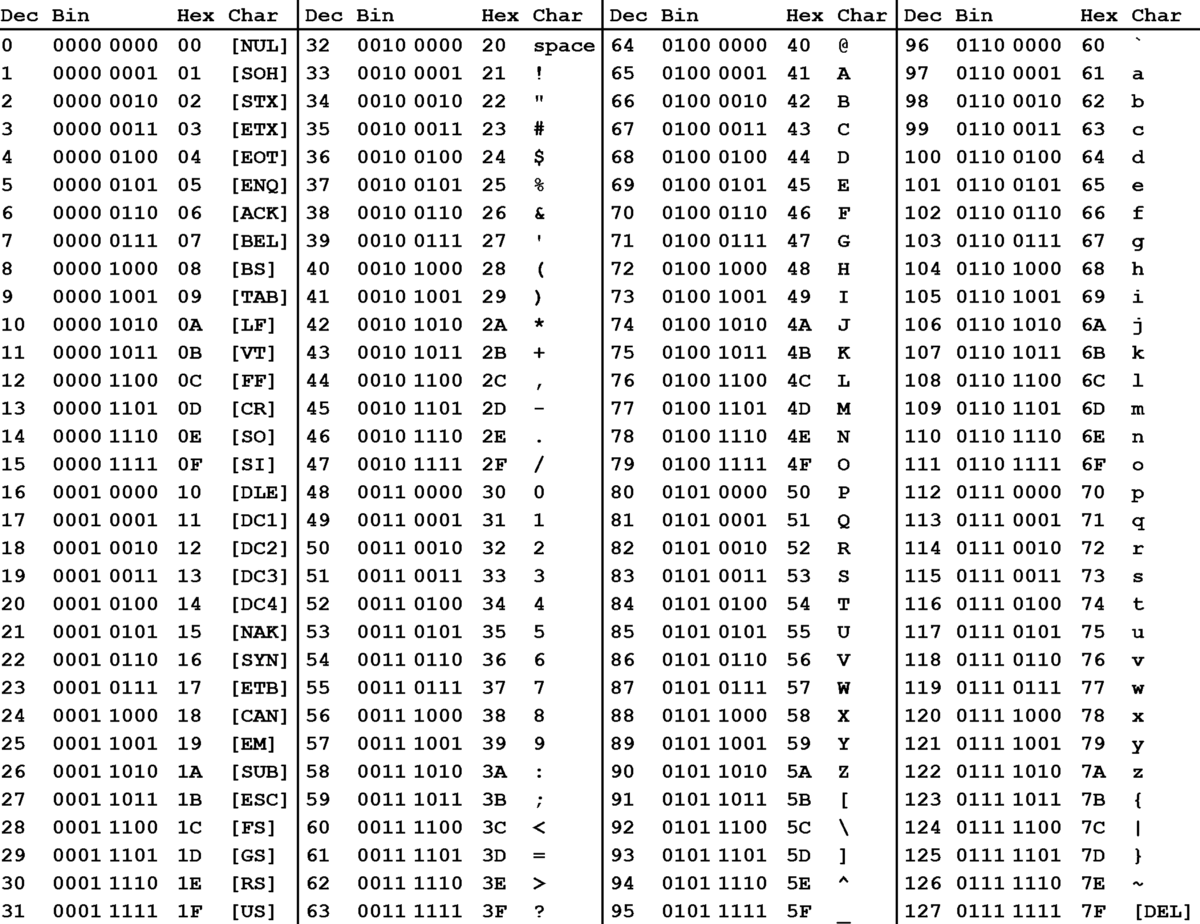
ASCII Table In Decimal, Binary and Hex
The character A is 0x41 in ASCII, The newline charater is 0x0A in ASCII and so on. This make the representation is straightforward as each character can be represented with single byte integer. Not all code in ASCII is printable. The first 32 character is considered control codes.
How About Strings?
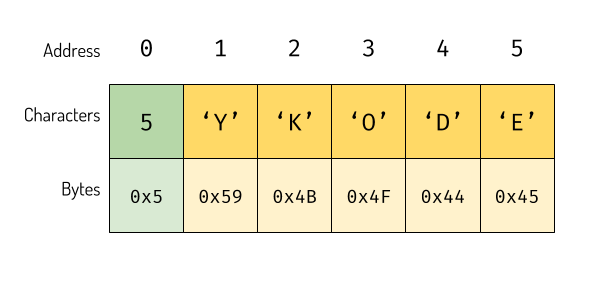
ASCII is about encoding single character but we communicate with words and sentences. We need a way to encode that too. Well, strings are array of characters. So we just put characters next to each other. The string YKODE in ASCII will be encoded as:
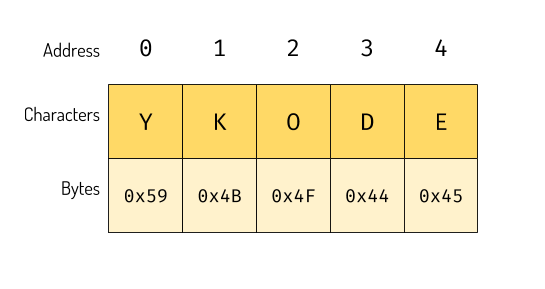
The encoding of ‘YKODE’ in ASCII
Unlike integers, which usually fixed in size, a word or sentences can be formed by arbitrary length of characters. This can be terminated or prefixed. The most common way is by terminating string is using the NUL character. This is how programming languages like C uses to say that the string is ended. The way of terminating ASCII string with NUL is called null terminated string.
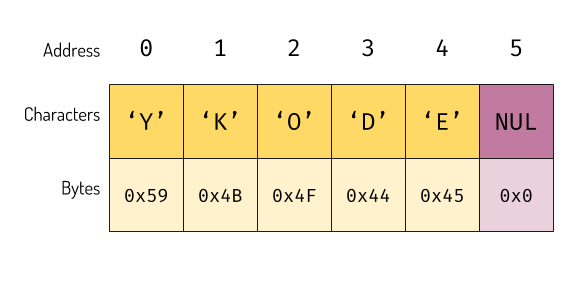
Null-Terminated String
The null-terminated string will occupy 𝑛+𝟷 bytes with 𝑛 is the character length of the string.
Other way of encoding string is by prefixing length in the front of the byte array. So we know in advance the length. The Pascal’s ShortString data type use this encoding. String sent to the network is usually sent using this format.
Pascal String
This way the length of the string can be determined by reading the first byte and interpret that as length and then read the next bytes as character. This has nice feature of having O(1) complexity when determining the length of the string. However, our string length is limited to the width of the prefix used. For single-byte prefix, the length of the string is limited to 255. The later version of Pascal and Delphi uses 4-bytes (32-bit) as prefix.
Your program can use either of them. The prefixing and terminating does not change the mapping between number and character. But for the sake of simplicity, I’ll just write the encoded characters from this point forward. Wether you’ll be terminating or prefixing depends on the use case and/or programming languages.
And then UNICODE came forth
Representing American text is simple with ASCII. I say, ‘American’ because IT IS US-centric, the ‘A’ in ASCII does not care about the rest of the world. It does not even contain £. The ASCII is extended to accommodate some accented characters, including £ sign. Everything below 127 is the same but above that is implementation-detail. The character encoding represented by numbers above 127 is specified in codepage. This where things get complicated because every codepage maps to different characters.
The US and UK uses codepage 437. Western Europe uses codepage 850. These codepages differs on some characters. The 0xC7 in codepage 437 is ╟ but in codepage 850 it is Ã. Asian languages such as Chinese and Japanese use thousands of characters. Chinese, in particular, uses two different encodings: Big5 for traditional chinese characters used in Taiwan, Hongkong, and Macau and GB for simplified chinese characters used in Mainland. Japanese de-facto standard is Shift-JIS. These asian encoding uses variable width in which each character can be represented by one or more bytes. This is a mess when combined to the internet where people can exchange information between geographies.
To make the exchange of information simpler, Unicode Consortium was created and incorporated. It defines every sensible writing system in use recently. It’s brave effort as defining what really is a letter or not may invoke political debate.
A common misconception about unicode, is that it’s 2-byte character set where every character is represented by 16-bit number. This notion is not correct. Unicode uses 32-bit code point. Wait, code point what is that?
Code Point and Encoding
Code point is 32-bit number to represent a character. From simple numbers and letters such as ‘N’ and ‘8’, a composite character such as Å, ligatures such as ﷺ or ॐ. So what’s the code points for “Hello世界”?

Codepoints of a unicode string
The string is just a bunch of codepoints. Codepoint is the mapping between character to a number. It’s denoted by U+prefix followed by a hexadecimal number.
To save them to disk on memory, we need a way to encode them. In the earliest time of unicode, we just encode in 2-byte (16-bit) integers. However, as you’ve learnt in the first series of integer representation this creates problems:
- To be able to correctly encode, we should agree on the endianess.
- ASCII characters needs twice the space.
- It’s not compatible with ASCII.
This early attempt to encode codepoints to two bytes integer has been a flop. Some operating system such as Windows even have two distinct API who accept ASCII and ‘wide char’. Windows still uses this 16-bit encoding until now.
Behold, the UTF-8
To solve problem with encoding with 16-bit integer. UTF-8 is made. An UTF-8 string can be 1–6 bytes wide. It’s totally compatible with ASCII. All ASCII characters are encoded to 1 byte. The rule of encoding a codepoint to UTF-8 is below
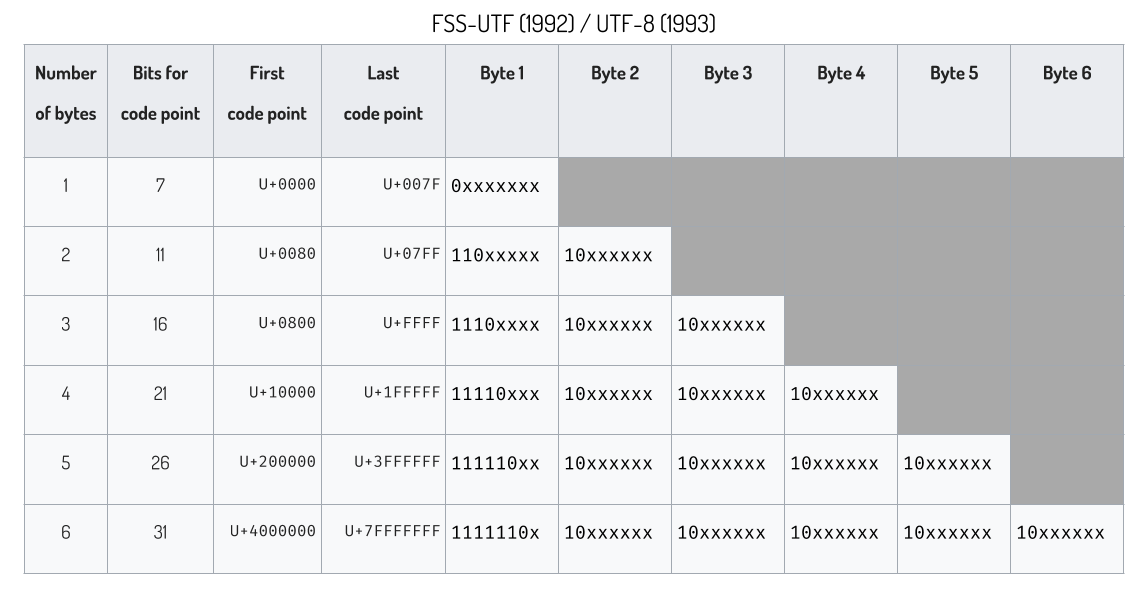
UTF-8 Encoding Rules
By using this rule we can encode “Hello 世界” in UTF-8. All character in “Hello” is in ASCII range, therefore it’s encoded as it is. So let’s focus on the last two Japanese Kanji characters.
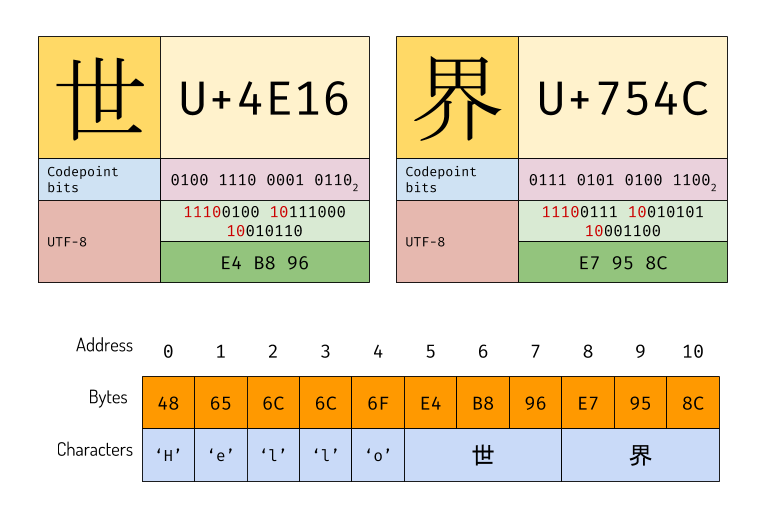
UTF-8 Encoding
You can see that the two characters occupy 3 bytes each. This also immune to endian difference because character is encoded in bytes. The only problem in UTF-8 is that the byte length and the string length is different. This is important to remember. The string ‘Hello世界’ has length of 7 and byte length of 10.
This poses problems to some programming languages or frameworks such as Python and Ruby. Python fixes the unicode problem in Python 3, and Ruby is problematic too.
Fixing Unicode for Ruby Developers
Java is also problematic as it terminates string with 2-bytes 0 representation, instead of 1 bytes. Languages that implement this correctly is Swift and Golang.
Testing in Swift
Swift has REPL that can be used to test our UTF-8 encoding. So let’s test it out
> let hello = "Hello世界"
hello: String = "Hello世界"
> print(hello.utf8.map{String($0, radix:16, uppercase:true)})
["48", "65", "6C", "6C", "6F", "E4", "B8", "96", "E7", "95", "8C"]
> hello.count
$R1: Int = 7
I think our manual calculation is correct. The second command in REPL is to convert each byte to a hex string so we can match with our manual calculation above. Swift also return correct character count.
Conclusion
Representing string of characters is a little bit complicated than we thought. As applications becomes more and more internationalised, UTF-8 will be way to go. It’s backward compatible with ASCII, and immune to endian difference as it operates in bytes.
In the next article, we’ll talk about how to represent floating point.