Building Microservices Within Bounded Context

If you’re being a software developer in 2017, you’ll at least heard the word “microservices” thrown around by fellow software developers. And sometimes you’ll heard the word “scalability” added for completeness. It’s look like if you’re not doing microservices, you’re not cool.
What The Heck Is Microservice?

Microservice Meme
Quoted from Martin Fowler: > Microservice is an approach to developing a single application as a suite of small services, each running its own process and communicating with lightweight mechanism, often an HTTP resources API. These services are built around business capabilities and independently deployable by fully automated deployment machinery. There’s a bare minimum of centralised management of those services, which may written in different programming languages and different storage.> — James Lewis and Martin Fowler
In other word, the whole application is made by composing several independent, self contained — deployable parts that works together and communicates.
The reason people implements Microservices Architecture are usually as follows:
- Faster response on business needs. Improving agility. It open opportunity to pivot and change business in timely manner versus sticking out to the rule that has been set and interdependence between components usually found in a monolith.
- Enable better customer experience. To be better improve the customer experience. We want to reduce churn. Especially if you have a service that customer can switch to your competitor without any effort.
- Cost reduction. When you want to expand, Microservices enable many business rules added quickly by only adhering contracts between services, avoiding high cost refactoring.
Microservices allows more agility on the software design than the Monolith. It allows less coordination between team to achieve results. Say, if we have identity service that manage user credentials and takes care about the security. In one point of time we want to implement two-factor authentication. If we have separate service, it’ll be faster to modify the login service only and left the other services unmodified.
Is Microservices Architecture For You?
Microservices is like neural network on your brain, Image Credits: https://www.flickr.com/photos/53416677@N08/4972916707)
I found out that Microservices is only logical if you have fairly complex business rules. If you have very simple CRUD business rules, Microservice Architecture only gives you another overhead on your operations. If you’re thinking about utilising Microservice Architecture, you need to take automation very seriously. Neglecting it is considered antipattern and will incur more costs in the long run.
Because Automation is one of the inseparable characteristics of microservices, building one requires a change of culture to automated unit testing, automated deployment, configuration management, service discovery, and quality assurance. Quality Assurance will take a huge role on doing unit, functional, and security testing during development.
If you cannot find a way to automate the testing and deployment, don’t do Microservices. Microservice without automation is waste of time and energy. You’ll be fighting with the deployment complexities rather than getting things done.
How To Build Microservices?

Microservices illustration
There are two ways building a Microservice-based applications.
- Building a monolith first and separate components as it goes.
- Building microservices from the beginning.
Either way, there will be a question on how we separate concerns to independent services. How small (or big) a service is?
Going back to the premise of Microservices, the separation of the services should be based on Business Capabilities. This is where people are usually tripped on. Engineers mostly focused on technical cohesion rather than functional cohesion in regards of reusability. They separate services in horizontally. Creating artificial interdependence between services, and introducing a tightly coupled system when any changes will bubble down the layer. There’s no single owner of business capabilities, because it’s spread too thin horizontally. This potentially creating a situation when each layer focusing on protecting their workflow from “outsider” (i.e another layer above or below), rather than focusing on delivering business capabilities. It defeats the purpose of having multiple services to encourage agility and removing interdependence.
The easy way of avoiding the pitfall of horizontally dividing layers is to think each service as if it is the product itself. Divide the whole product to small contexts. Each service is a representative of a specific domain. If you ever study or implement Domain Driven Design, the smallest unit is the Bounded Context to be able to be deployed as its own independent services.
Layered Service Anti-Pattern
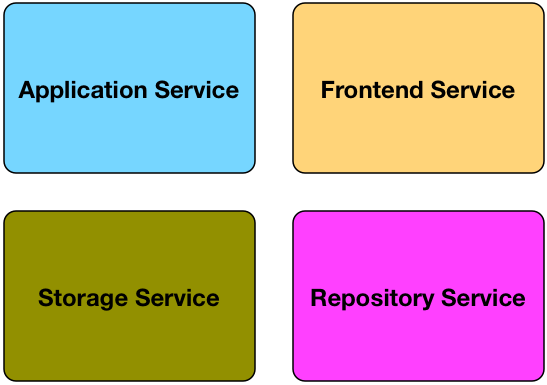
Layered Service Anti-Pattern
We have storage service to expose SQL to the repository service. Repository service provides interface and act as data access layer which provides models to application service. Application Service expose all APIs to the front-end services.
Now we have delivery dependency whenever there’s changes or improvements on business logic because there are a lot of out of process calls happening. The separation of concern serves technical concern and no business value because business logic is scattered throughout every layer. We end up with something that resembles monolith with a lot of network calls. That’s very bad because now we need to handle network edge cases which we don’t need on a monolithic application. This services architecture is not composable and only increase complexity without delivering any value.
Define Service By Bounded Context
If we divide the e-commerce business logic by contexts we may end up with following set of services:
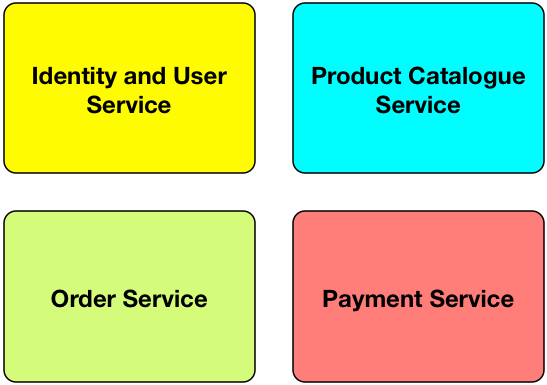
e-Commerce Services, Divided By Context
Now we divide the software into services that serve a specific business capabilities. Each of them can have different stack of technology, and be made by an independent team from storage up to the UI. It’s advisable for each of the service does not share code. Each individual service does not share common database schema because that would mean tight coupling. If services share database schema, there will be a situation where you change database schema and render your application completely useless.
Because each of the services is made by their own respective team, they’d need something to be able to communicate. That’s where the contract between services comes into play. It’s advisable to use a standard protocol such as REST and Protocol Buffers for communication with other services.
Share Nothing
The ultimate goal of building microservices is make services share nothing. Each type of service cannot have shared storage. For example, a product catalogue service cannot have access to user storage. There’s no assumption that the services will run in the same machine or in the same data centre.
By using contract mentioned above, a service can ask another service for some data they need. For example, an Order Service may want to know the data of the user and the item bought. The service can ask the identity service for the data it needs and product catalogue service to get the item price. It copies the required information and save to its Order table. When the user do payment, it wil ask Order Service for the order information, get the total price and execute the payment. Payment Service will then save the receipt to its own storage containing some information it gets from the Order Service.
Up until this point we discover some of the characteristic, or rule of thumb where we building or refactoring Microservices:
- Vertical Decomposition. The system is divided into specific vertical with its own team, storage, and technology stack. It serves one business capabilities and domain.
- Shared Nothing. There’s no shared mutable state between services. There should no shared HTTP sessions. However, multiple instances of a service could share a database.
- Data Ownership. For each context, there’s only one service in charge. Other system could ask for read only access to the data provider using agreed protocol. Use the copy of data and extract the information needed to the service storage.
These three characteristics can easily be implemented if we’re using CQRS Pattern. But that is out of this article scope.
Deployment and Scaling Up
Scaling up a microservices is actually pretty straightforward. Gather data as much as possible about the characteristics of each services. In our example, Product Catalogue service there will be a lot of read access. This way we may implement a cache strategy to increase the throughput of the service as well as using a storage that is optimised for read and cache the contents aggressively on many levels.
The first common step for scaling is making cluster of your service in the same context with share database. Did I say it’s better to share nothing? Well yes. But sometimes we want to scale gradually, implementing share nothing architecture while handling on concurrency, locks, and consistency is not an easy feat. The same kind of service shares storage/database. It can lead to the bottleneck due to shared write and table lock.
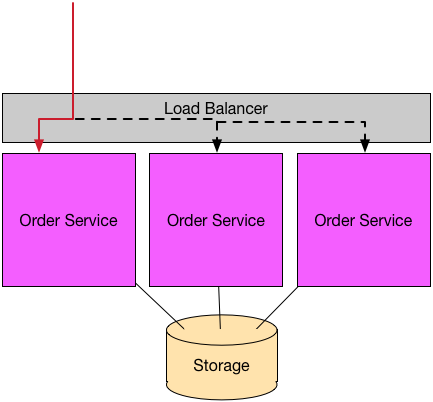
Shared storage in the same services
As you can see, many instances of services within the same context can share database. It’s so often that a load-balanced applications do that. This set up, however, may lead to bottleneck due to shared write. This can be done by scaling the storage too. In many cases, we don’t need a strong consistency even for banking system. In this case, an eventual consistency storage with better availability may be a wise choice. An architectural pattern such as Command-Query Responsibility Segregation and Event Sourcing maybe better suited for more scalable software architecture.
Deployment
Continuous Integration
A system consists of multiple small services written by agile team needs to be deployed in timely manner. Managing a cluster of small services is not easy. This is a huge shift of the culture. A team that deploy a microservice needs to have these:
- A disciplined coding practice. Because in Microservices there are a lot of moving parts, a disciplined coding pratices is needed. Developers should be able to deliver a high quality, clean, and fully tested code.
- A complete test. All kind of automated tests on every layer and environment. Team needs to be very disciplined on writing unit tests, all the way up to integration tests on every tier. For example we have three environments: dev, staging, and production. For a code to be able to be promoted from dev to staging, it needs to pass all the tests happening on dev. The higher risk the environment, the stricter the rule. For example, if dev environment needs only to pass all the unit tests and integration tests. A staging environment needs to pass a performance testing to be able to be promoted to production environment.
- An automated infrastructure. Microservices with manual configuration is an antipattern. These are the infrastructure needed to build a microservice:
- A clear versioning semantics. You can use Semantic Versionng for this. It’s widely used and understood.
- A source code control and good branching system. It looks like Git andMercurial is dominant nowadays. Create a branching system that allows you to easily deploy your software. I’m using a rebase workflow. There are a lot of arguments on the workflows. I choose rebasing because it creates a straight tree that easy to be rolled back and easy to maintain.
- A build system. Jenkins is very common to be used on this space. Use it to build the artifacts for every part of the services end-to-end. Never build anything manually.
- A configuration management and service discovery. You should be able to spawn a new instane of a service and register it presence and read the config right after it’s launched without extra human touch. There are two widely used software: Zookeeper and Consul.io.
- An orchestration tool. We want be able to provision and update our clusters automatically. For this, Ansible is also widely used.
- A dashboard. Gather your server performance data. There are many SaaS over there that do this so you don’t need to write it yourself. DataDog and New Relic are widely used for this purpose.
All of above ingredients are essential for successful microservice development and deployment. Those are things needed to avoid most of the microservice anti-pattern.
Conclusion
Microservices are made for a purpose. It enables the business to move more rapidly, new features shipped quickly in a fine-grained services and team. Building microservices, however, need a disciplined platform.
I hope this article gives you something to ponder about to evaluate your current architecture. Start small, divide your system into domains, isolate it, and deploy it independently. Implement unit tests, and integration tests as early as possible and works towards microservices infrastructure from there.